[In the series ‘Explain this to me like I’m a manager’]
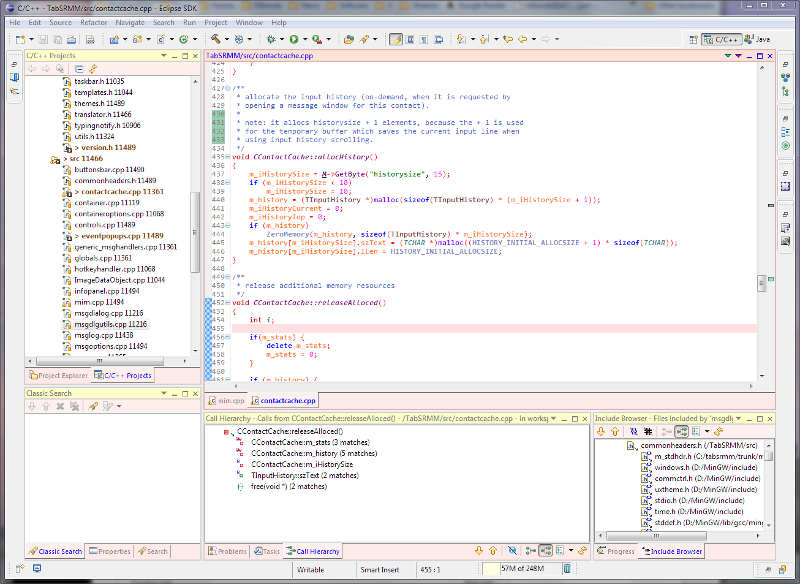
Let’s imagine you are paid to write emails.
The company you work for has a policy that all public emails from an executive should be written by someone with a clear head and proper training. That someone is you.
It works like this:
- You receive an in-person briefing from the executive of what the email is about.
- You go back to your office to work on the email. In case a question arises, you phone the executive and usually get an answer right away.
- When finished, you present your email and edit it together until you’re both satisfied with the result.
The whole process takes about half an hour up to several hours.
This seems OK. It might even be kind of fun, right?
Now, imagine a different way of working
The only difference is that you’re not sure when you’ll get feedback or approval. It might be right away, or it might take several weeks.
Since you don’t know how long it’ll take, you start working on the next task. Instead of having 1 email “in progress,” you might have 20, 30 or a whole lot more.
This the exact same job, with the same input, but it seems much more cumbersome and a lot less fun, or not?
Well, unfortunately, this is the way most developers are working
In this example, we’re assuming there is no middleman (PM, analyst…) through whom all communication passes, introducing his or her own ideas, obfuscating the message in the process.
As a developer, I have often found it very frustrating when it takes ages to get feedback or answers.
You start working on something. You get stuck, you need feedback. Because you don’t know when you’ll get answers, you put the task on hold and start working on the next one.
But wait, the client has the exact same frustration!
Yes, I’ve been there: for several years, I worked on the other side, steering contractors/freelancers to develop custom software for our organization.
It is just as annoying to give extensive feedback to a developer, only to get additional questions 2 weeks later. These questions are usually ones that could have easily been answered if asked right away, but 2 weeks later, I can hardly remember what it was all about!
Surely, there are better ways to waste my time!
What is the engineer’s solution?
Let’s use a tool to manage all this “work in progress”, with statuses, flags, due dates, source integration, custom fields, assigned persons, reports, milestones and all that jazz.
This is an often unnecessary over-complication that is regarded as standard practice.
“That’s how it’s done!”
There are indeed situations that demand this way of working.
But, most of the software projects out there are actually quite straightforward and don’t benefit from these “solutions.”
The root cause is still there: it takes too long to receive feedback. As humans, we can’t temporarily store our built-up understanding—our “grasp”—somewhere until we need it again.
So, what’s the alternative?
We are all busy and we can’t just drop what we’re working on whenever someone demands our attention. But what if we could?
What if we could work on 2-3 tasks at the same time?
What if we didn’t need tools (except for a basic to-do list) to manage the progress of all our tasks?
What if we could work intensely with the client on a few tasks from beginning to end? And not start a new task until these were actually completely finished?
Why am I asking these questions? Because it would save time, money and frustration!
This is one of the core elements of several task/project management frameworks that suggest focusing on a limited number of tasks during so-called “sprints,” or that impose a limit on the “work in progress” (a WIP limit).
Often advocated. Seldom practiced.

And really, no one is asking you to drop everything at every question; just don’t let things slide forever.
Do we really waste that much time waiting for feedback?
There was a study, conducted at Palm in California, the makers of the first PDAs. This study measured how much longer it takes a developer to fix a bug detected 3 weeks later instead of on the same day.
Now, how much longer do you think it takes?
About twenty-four times as much, no matter if the task is big or small.
Did you also fall off your chair? My initial guess was 5-10 times, which should be enough to inspire anyone to give this some additional thought.

But waiting endlessly for feedback isn’t the only cause of WIP explosion!
It’s also:
- The delay between analysis and development
- The delay between development and testing (if you use testers)
- The delay between a developer reading the tester’s feedback and acting upon it
- Waiting for approval or a sign-off on something
- …
Now, how do we fix this?
Well, it’s not that hard… to write about! 🙂
Here are my suggestions, which should work no matter what role you’re in:
- Try to get everyone on board. Send them the link to this article. Or send them this excerpt from The Scrum Book; the author is just a bit more known than me, so it might work better! 😉
- Lead by example: give feedback and answer questions on the same day or at least within 24 hours.
- Explicitly state that you try to give feedback asap. Actively request the same from everyone you work with, including clients and managers. Follow up if necessary. A lot of people let things slide until they notice you’re consistently following up.
And, if your role allows:
- Try to get everyone (necessary/needed) working on roughly the same task(s) at the same time.
- Try to limit the number of tasks and the “work in progress.” Impose a WIP limit.
- Cut the number of in-between-persons. They often serve no real purpose, except to consolidate or translate information. Developers often communicate too technically. I still make this mistake myself. But I also believe you can learn to communicate on a more non-tech human level. Listen to what is really being said, and try to respond at the same level using the same words.
I think it’s always better to have direct communication lines because it improves the possibility of learning from each other.
But I’m a developer. I can’t just demand my client’s attention!
You’re not demanding immediate attention; you’re asking not to wait for ages to get a reply.
I know this is not the standard way of working for a lot of developers: being proactive instead of reactive, reaching out instead of tackling that next user story or bug. I don’t mean to be condescending. I speak from my own practice, from the mistakes I’ve made, from experiences with failed as well as successful projects.
This might be one step (of many) to becoming a “10x engineer” and to show that you’re on top of things and care about the project.
Remember, all those non-tech people you’re working with really don’t know much about software development.
There’s nothing wrong with steering and educating them on how to optimize the process and save time and money. Who could be against that? (Unless, of course, your time is billed by the hour 😉
… And what if you get feedback from multiple sources, contradicting each other, even contradicting your own opinion?
Tackling “Design by Committee” is another story. Sign up here and stay informed.